
Android предоставляет эталонную реализацию всех компонентов, необходимых для реализации платформы виртуализации Android. В настоящее время эта реализация ограничена архитектурой ARM64. На этой странице объясняется архитектура платформы.
Фон
Архитектура Arm допускает до четырех уровней исключений, при этом уровень исключений 0 (EL0) является наименее привилегированным, а уровень исключений 3 (EL3) — наиболее привилегированным. Большая часть кода Android (все компоненты пользовательского пространства) работает на уровне EL0. Остальная часть того, что обычно называют «Android», — это ядро Linux, которое работает на уровне EL1.
Уровень EL2 позволяет внедрить гипервизор, обеспечивающий изоляцию памяти и устройств в отдельные виртуальные машины pVM на уровнях EL1/EL0 с надежными гарантиями конфиденциальности и целостности.
Гипервизор
Защищенная виртуальная машина на основе ядра (pKVM) построена на базе гипервизора Linux KVM , который был расширен возможностью ограничения доступа к полезным нагрузкам, работающим в гостевых виртуальных машинах, помеченных как «защищенные» при создании.
KVM/arm64 поддерживает различные режимы выполнения в зависимости от доступности определенных функций ЦП, а именно, расширений виртуализации хоста (VHE) (ARMv8.1 и более поздние версии). В одном из этих режимов, обычно известном как режим без VHE, код гипервизора выделяется из образа ядра во время загрузки и устанавливается на уровне EL2, в то время как само ядро работает на уровне EL1. Хотя компонент EL2 KVM является частью кодовой базы Linux, это небольшой компонент, отвечающий за переключение между несколькими уровнями EL1. Компонент гипервизора компилируется вместе с Linux, но находится в отдельном, выделенном разделе памяти образа vmlinux . pKVM использует эту конструкцию, расширяя код гипервизора новыми функциями, позволяющими накладывать ограничения на ядро Android-хостинга и пользовательское пространство, а также ограничивать доступ хоста к памяти гостевой системы и гипервизору.
модули поставщика pKVM
Модуль поставщика pKVM — это аппаратный модуль, содержащий специфические для устройства функции, такие как драйверы блока управления памятью ввода-вывода (IOMMU). Эти модули позволяют переносить в pKVM функции безопасности, требующие доступа уровня исключений 2 (EL2).
Чтобы узнать, как реализовать и загрузить модуль поставщика pKVM, обратитесь к разделу «Реализация модуля поставщика pKVM» .
процедура загрузки
На следующем рисунке показана процедура загрузки pKVM:
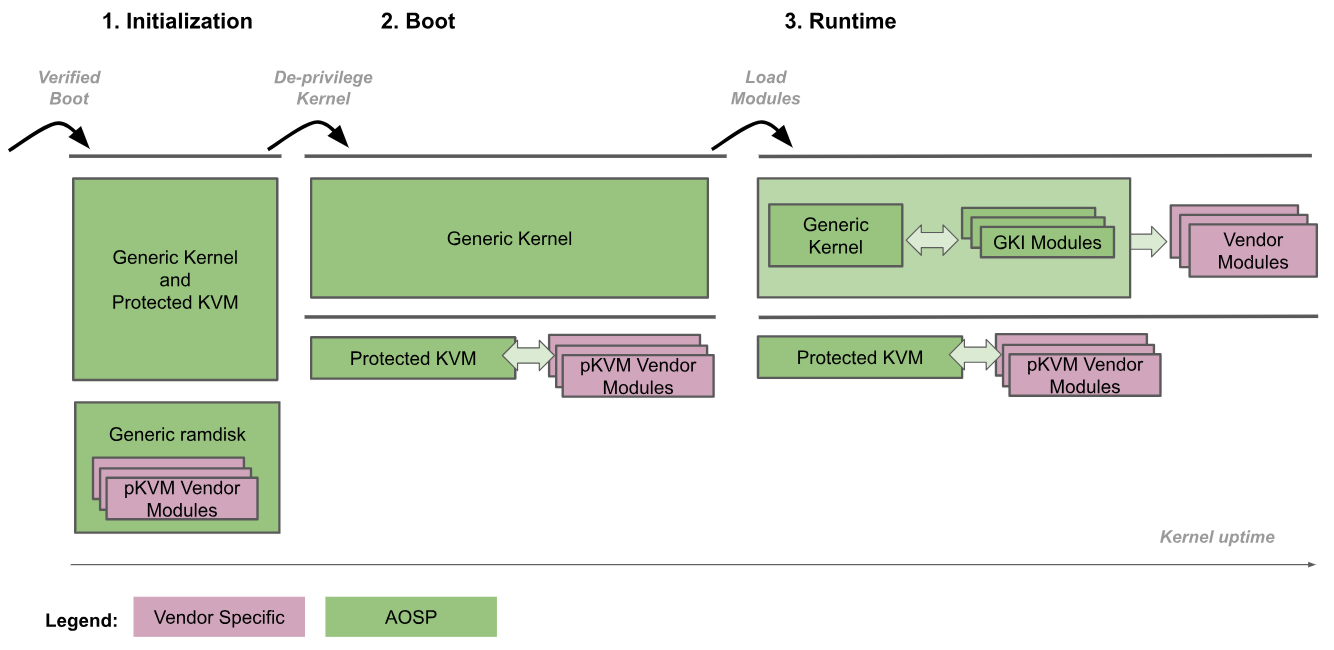
- Инициализация: Загрузчик переходит в универсальное ядро на уровне EL2. Затем доверенный код ядра на уровнях EL2 и EL1 инициализирует pKVM и его модули. На этом этапе EL1 считается доверенным для EL2, поэтому недоверенный код не выполняется.
- Ядро с понижением привилегий: универсальное ядро определяет, что работает на уровне EL2, и понижает свои привилегии до EL1. pKVM и его модули продолжают работать на уровне EL2.
- В процессе выполнения : стандартное ядро продолжает загрузку в обычном режиме, загружая все необходимые драйверы устройств до достижения пользовательского пространства. На этом этапе pKVM уже подключен и обрабатывает таблицы страниц второго этапа.
Процедура загрузки полагается на загрузчик в проверке и поддержании целостности образа ядра на этапе инициализации. После того, как ядро теряет свои привилегии, оно перестает считаться доверенным для гипервизора, который затем несет ответственность за свою защиту, даже если ядро будет скомпрометировано.
Наличие ядра Android и гипервизора в одном бинарном образе позволяет создать очень тесно связанный интерфейс связи между ними. Эта тесная связь гарантирует атомарные обновления двух компонентов, что избавляет от необходимости поддерживать стабильность интерфейса между ними и обеспечивает большую гибкость без ущерба для долгосрочной поддержки. Тесная связь также позволяет оптимизировать производительность, когда оба компонента могут взаимодействовать, не влияя на гарантии безопасности, предоставляемые гипервизором.
Кроме того, внедрение GKI в экосистему Android автоматически позволяет развертывать гипервизор pKVM на устройствах Android в том же исполняемом файле, что и ядро.
защита доступа к памяти ЦП
Архитектура Arm предусматривает блок управления памятью (MMU), разделённый на два независимых этапа, каждый из которых может использоваться для реализации трансляции адресов и управления доступом к различным частям памяти. MMU первого этапа управляется модулем EL1 и обеспечивает первый уровень трансляции адресов. MMU первого этапа используется Linux для управления виртуальным адресным пространством, предоставляемым каждому процессу пользовательского пространства, а также его собственным виртуальным адресным пространством.
Блок управления памятью (MMU) второго этапа управляется модулем EL2 и позволяет применять второе преобразование адреса к выходному адресу MMU первого этапа, в результате чего получается физический адрес (PA). Преобразование второго этапа может использоваться гипервизорами для управления и преобразования обращений к памяти из всех гостевых виртуальных машин. Как показано на рисунке 2, когда оба этапа преобразования включены, выходной адрес первого этапа называется промежуточным физическим адресом (IPA). Примечание: виртуальный адрес (VA) преобразуется в IPA, а затем в PA.
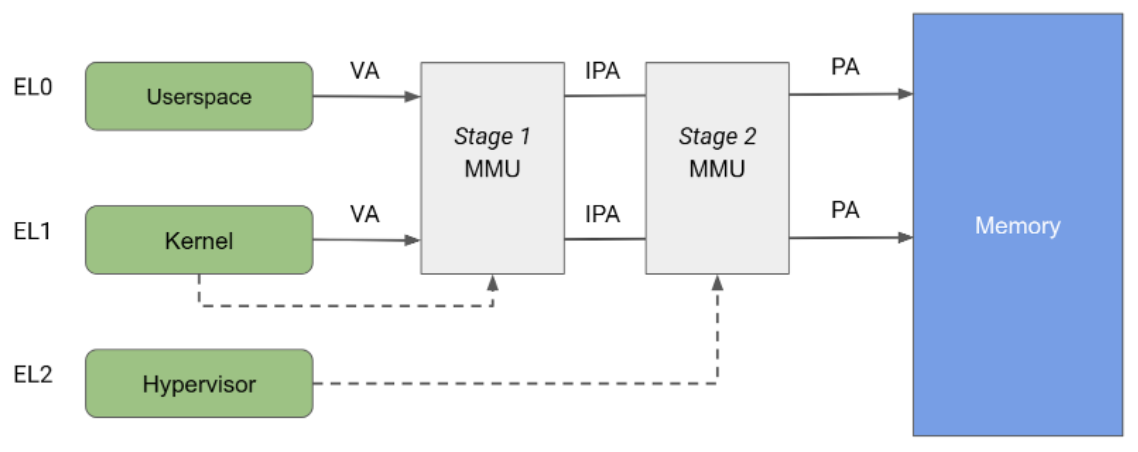
Исторически сложилось так, что KVM работает с включенной трансляцией уровня 2 во время работы гостевых систем и с отключенной трансляцией уровня 2 во время работы ядра Linux хоста. Такая архитектура позволяет обращениям к памяти из блока управления памятью уровня 1 хоста проходить через блок управления памятью уровня 2, обеспечивая тем самым неограниченный доступ хоста к страницам памяти гостевой системы. С другой стороны, pKVM включает защиту уровня 2 даже в контексте хоста и передает ответственность за защиту страниц памяти гостевой системы гипервизору, а не хосту.
KVM в полной мере использует трансляцию адресов на втором этапе для реализации сложных отображений IPA/PA для гостевых систем, что создает иллюзию непрерывной памяти для гостевых систем, несмотря на физическую фрагментацию. Однако использование MMU второго этапа для хоста ограничено только контролем доступа. Второй этап хоста использует отображение по идентификаторам, гарантируя, что непрерывная память в пространстве IPA хоста будет непрерывной в пространстве PA. Такая архитектура позволяет использовать большие отображения в таблице страниц и, следовательно, снижает нагрузку на буфер трансляции адресов (TLB). Поскольку отображение по идентификаторам может индексироваться по PA, второй этап хоста также используется для отслеживания принадлежности страниц непосредственно в таблице страниц.
Защита прямого доступа к памяти (DMA)
Как было описано ранее, удаление страниц гостевой системы из таблиц страниц Linux в ЦП является необходимым, но недостаточным шагом для защиты памяти гостевой системы. pKVM также должен защищать от доступа к памяти со стороны устройств с поддержкой DMA, находящихся под управлением ядра хоста, и от возможности атаки DMA, инициированной злонамеренным хостом. Чтобы предотвратить доступ таких устройств к памяти гостевой системы, pKVM требует наличия аппаратного блока управления памятью ввода-вывода (IOMMU) для каждого устройства с поддержкой DMA в системе, как показано на рисунке 3.
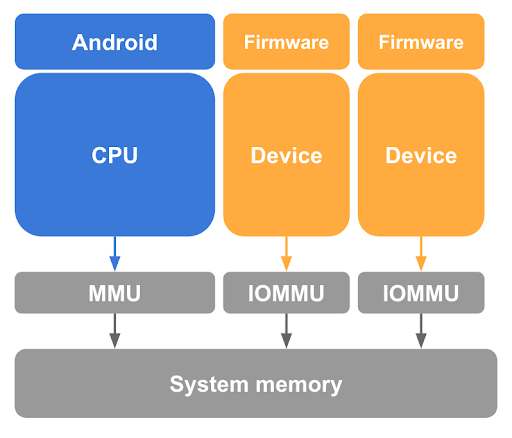
Как минимум, аппаратное обеспечение IOMMU предоставляет средства для предоставления и отзыва доступа на чтение/запись для устройства к физической памяти на уровне страниц. Однако это аппаратное обеспечение IOMMU ограничивает использование устройств в pVM, поскольку они предполагают использование второго этапа отображения идентификаторов.
Для обеспечения изоляции между виртуальными машинами транзакции памяти, генерируемые от имени различных сущностей, должны быть различимы для IOMMU, чтобы для трансляции можно было использовать соответствующий набор таблиц страниц.
Кроме того, сокращение объема кода, специфичного для SoC, на уровне EL2 является ключевой стратегией для уменьшения общей базы доверенных вычислений (TCB) pKVM и противоречит включению драйверов IOMMU в гипервизор. Для решения этой проблемы хост на уровне EL1 отвечает за вспомогательные задачи управления IOMMU, такие как управление питанием, инициализация и, при необходимости, обработка прерываний.
Однако передача управления состоянием устройства хосту накладывает дополнительные требования на программный интерфейс оборудования IOMMU, чтобы гарантировать, что проверки разрешений не могут быть обойдены другими способами, например, после перезагрузки устройства.
Стандартной и хорошо поддерживаемой архитектурой IOMMU для устройств Arm, обеспечивающей как изоляцию, так и прямое назначение памяти, является архитектура блока управления системной памятью Arm (SMMU). Эта архитектура является рекомендуемым эталонным решением.
владение памятью
При загрузке вся память, не относящаяся к гипервизору, считается принадлежащей хосту и отслеживается гипервизором как таковая. При запуске виртуальной машины pVM хост выделяет страницы памяти для ее загрузки, и гипервизор передает право собственности на эти страницы от хоста к pVM. Таким образом, гипервизор устанавливает ограничения контроля доступа в таблице страниц второго этапа хоста, чтобы предотвратить повторный доступ к этим страницам, обеспечивая конфиденциальность гостевой системы.
Взаимодействие между хостом и гостевыми системами обеспечивается контролируемым совместным использованием памяти. Гостевым системам разрешается делиться частью своих страниц с хостом с помощью гипервызова, который дает указание гипервизору переназначить эти страницы в таблице страниц второго этапа хоста. Аналогичным образом, взаимодействие хоста с TrustZone обеспечивается совместным использованием памяти и/или операциями предоставления доступа к памяти, которые тщательно контролируются pKVM с использованием спецификации Firmware Framework for Arm (FF-A) .
Поскольку требования к памяти pVM могут меняться со временем, предусмотрен гипервызов, позволяющий освободить хосту права собственности на указанные страницы, принадлежащие вызывающей стороне. На практике этот гипервызов используется с протоколом virtio balloon, чтобы позволить VMM запрашивать память у pVM и чтобы pVM уведомлял VMM об освобожденных страницах контролируемым образом.
Гипервизор отвечает за отслеживание принадлежности всех страниц памяти в системе и за то, используются ли они совместно или предоставляются другим сущностям. Большая часть отслеживания состояния осуществляется с помощью метаданных, прикрепленных к таблицам страниц второго этапа хоста и гостевых систем, используя зарезервированные биты в записях таблиц страниц (PTE), которые, как следует из названия, зарезервированы для использования программным обеспечением.
Хост должен гарантировать, что он не будет пытаться получить доступ к страницам, которые были сделаны недоступными гипервизором. Несанкционированный доступ хоста приводит к тому, что гипервизор внедряет в хост синхронное исключение, что может либо привести к получению ответственной задачей пользовательского пространства сигнала SEGV, либо к сбою ядра хоста. Для предотвращения случайных обращений страницы, переданные гостевым системам, становятся недоступными для обмена или слияния ядром хоста.
Обработка прерываний и таймеры
Прерывания являются неотъемлемой частью взаимодействия гостевой системы с устройствами и обеспечивают связь между процессорами, при этом межпроцессорные прерывания (IPI) являются основным механизмом связи. В модели KVM управление виртуальными прерываниями делегируется хосту в EL1, который в этом случае выступает в роли ненадежной части гипервизора.
pKVM предлагает полную эмуляцию контроллера прерываний Generic Interrupt Controller версии 3 (GICv3) на основе существующего кода KVM. Таймеры и межпроцессные прерывания обрабатываются в рамках этого ненадежного кода эмуляции.
поддержка GICv3
Интерфейс между EL1 и EL2 должен обеспечивать доступ хоста EL1 ко всему состоянию прерываний, включая копии регистров гипервизора, связанных с прерываниями. Обычно это достигается с помощью областей общей памяти, по одной на каждый виртуальный ЦП (vCPU).
Код поддержки системных регистров во время выполнения можно упростить, чтобы он поддерживал только перехват событий регистров Software Generated Interrupt Register (SGIR) и Deactivate Interrupt Register (DIR). Архитектура требует, чтобы эти регистры всегда перехватывали события уровня EL2, в то время как другие перехваты пока полезны только для устранения ошибок. Все остальное обрабатывается аппаратно.
На стороне MMIO все эмулируется на EL1, используя всю существующую инфраструктуру KVM. Наконец, сигнал ожидания прерывания (WFI) всегда передается на EL1, поскольку это один из основных примитивов планирования, используемых KVM.
Поддержка таймера
Значение компаратора для виртуального таймера должно передаваться в EL1 через каждый блокирующий WFI, чтобы EL1 мог внедрять прерывания таймера, пока виртуальный ЦП заблокирован. Физический таймер полностью эмулируется, и все ловушки передаются в EL1.
Обработка MMIO
Для связи с монитором виртуальных машин (VMM) и выполнения эмуляции GIC необходимо передавать ловушки MMIO обратно на хост в EL1 для дальнейшей обработки. Для работы pKVM требуется следующее:
- IPA и размер доступа
- Данные в случае записи
- Порядок байтов процессора в момент перехвата
Кроме того, ловушки, в которых в качестве источника/получателя используется регистр общего назначения (GPR), передаются с помощью абстрактного псевдорегистра передачи.
Гостевые интерфейсы
Гостевая система может взаимодействовать с защищенной гостевой системой, используя комбинацию гипервызовов и доступа к памяти в перехваченных областях. Гипервызовы предоставляются в соответствии со стандартом SMCCC , при этом диапазон зарезервирован для выделения поставщиком KVM. Следующие гипервызовы имеют особое значение для гостевых систем pKVM.
Типовые гипервызовы
- PSCI предоставляет гостевой системе стандартный механизм для управления жизненным циклом виртуальных процессоров, включая переход в спящий режим, отключение и завершение работы системы.
- TRNG предоставляет стандартный механизм для запроса энтропии гостевой системой у pKVM, которая перенаправляет запрос в EL3. Этот механизм особенно полезен в тех случаях, когда хосту нельзя доверять виртуализацию аппаратного генератора случайных чисел (ГСЧ).
гипервызовы pKVM
- Совместное использование памяти с хостом. Вся память гостевой системы изначально недоступна для хоста, но доступ хоста необходим для обмена данными через общую память и для паравиртуализированных устройств, использующих общие буферы. Гипервызовы для совместного использования и отмены совместного использования страниц с хостом позволяют гостевой системе точно определять, какие части памяти будут доступны остальной части Android без необходимости установления соединения.
- Освобождение памяти хостом. Вся память гостевой системы обычно принадлежит ей до момента её уничтожения. Это состояние может быть недостаточным для долгоживущих виртуальных машин с меняющимися со временем потребностями в памяти. Гипервызов
relinquishпозволяет гостевой системе явно передать право собственности на страницы обратно хосту без необходимости завершения работы гостевой системы. - Перехват доступа к памяти хостом. Традиционно, если гостевая система KVM обращается к адресу, не соответствующему допустимой области памяти, поток vCPU завершает работу с хостом, и доступ обычно используется для MMIO и эмулируется VMM в пользовательском пространстве. Для упрощения этой обработки pKVM должен передавать хосту подробную информацию об ошибке, такую как адрес, параметры регистров и, возможно, их содержимое, что может непреднамеренно раскрыть конфиденциальные данные защищенной гостевой системы, если перехват не был предвиден. pKVM решает эту проблему, рассматривая эти ошибки как фатальные, если гостевая система ранее не выполнила гипервызов для идентификации диапазона IPA, вызвавшего ошибку, как диапазона, для которого разрешен перехват доступа с отправкой на хост. Это решение называется защитой MMIO .
Виртуальное устройство ввода-вывода (virio)
Virtio — это популярный, портативный и зрелый стандарт для реализации и взаимодействия с паравиртуализированными устройствами. Большинство устройств, доступных для защищенных гостевых систем, реализованы с использованием Virtio. Virtio также лежит в основе реализации vsock, используемой для связи между защищенной гостевой системой и остальной частью Android.
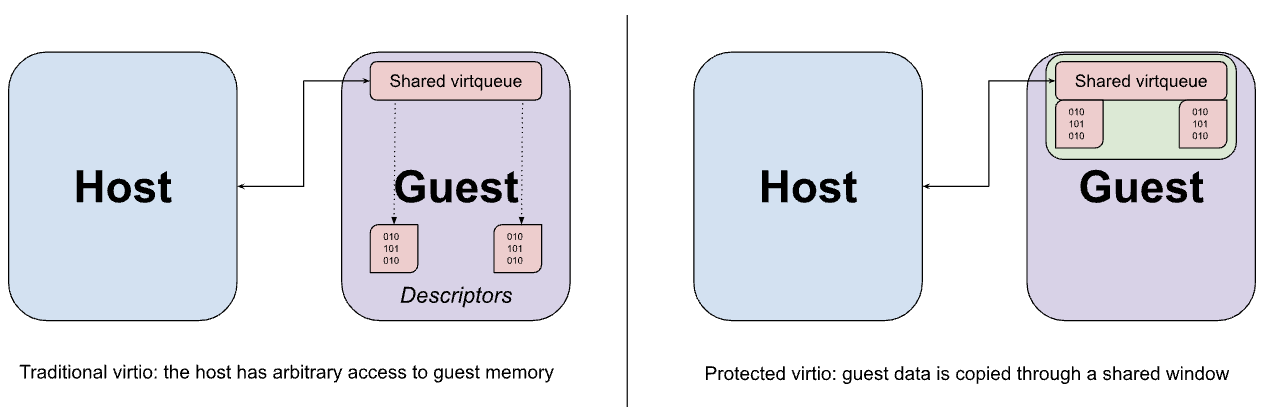
Устройства virtio обычно реализуются в пользовательском пространстве хоста с помощью VMM, которая перехватывает заблокированные обращения к памяти гостевой системы через интерфейс MMIO устройства virtio и эмулирует ожидаемое поведение. Доступ к MMIO относительно затратен, поскольку каждое обращение к устройству требует обмена данными с VMM и обратно, поэтому большая часть фактической передачи данных между устройством и гостевой системой происходит с использованием набора очередей virtqueue в памяти. Ключевое предположение virtio заключается в том, что хост может произвольно обращаться к памяти гостевой системы. Это предположение очевидно в проектировании очереди virtqueue, которая может содержать указатели на буферы в гостевой системе, к которым эмуляция устройства предназначена для прямого доступа.
Хотя описанные ранее гипервызовы для совместного использования памяти могли бы использоваться для обмена буферами данных virtio между гостевой системой и хостом, этот обмен обязательно выполняется на уровне страниц и может привести к раскрытию большего объема данных, чем требуется, если размер буфера меньше размера страницы. Вместо этого гостевая система настроена на выделение как очередей виртуальных процессов (virtqueues), так и соответствующих им буферов данных из фиксированного окна общей памяти, при этом данные копируются (перенаправляются) в это окно и из него по мере необходимости.
Взаимодействие с TrustZone
Хотя гостевые системы не могут напрямую взаимодействовать с TrustZone, хост всё равно должен иметь возможность отправлять вызовы SMC в защищённую среду. Эти вызовы могут указывать на физически адресуемые буферы памяти, недоступные для хоста. Поскольку защищённое программное обеспечение, как правило, не знает о доступности буфера, злонамеренный хост может использовать этот буфер для выполнения атаки с использованием запутанного заместителя (аналогичной атаке DMA). Для предотвращения таких атак pKVM перехватывает все вызовы SMC хоста на уровне EL2 и выступает в качестве прокси между хостом и защищённым монитором на уровне EL3.
Вызовы PSCI от хоста перенаправляются в микропрограмму EL3 с минимальными изменениями. В частности, точка входа для процессора, подключающегося к сети или выходящего из спящего режима, переписывается таким образом, что таблица страниц второго этапа устанавливается на уровне EL2, прежде чем вернуться к хосту на уровне EL1. Во время загрузки эта защита обеспечивается pKVM.
Данная архитектура основана на поддержке PSCI в SoC, предпочтительно с использованием актуальной версии TF-A в качестве прошивки EL3.
Стандарт Firmware Framework for Arm (FF-A) стандартизирует взаимодействие между обычной и защищенной средами, особенно при наличии защищенного гипервизора. Значительная часть спецификации определяет механизм совместного использования памяти с защищенной средой, используя как общий формат сообщений, так и четко определенную модель разрешений для базовых страниц. pKVM выступает в качестве прокси для сообщений FF-A, чтобы гарантировать, что хост не пытается совместно использовать память с защищенной стороной, для которой у него нет достаточных прав.
Эта архитектура основана на программном обеспечении защищенной среды, обеспечивающем соблюдение модели доступа к памяти, чтобы гарантировать, что доверенные приложения и любое другое программное обеспечение, работающее в защищенной среде, могут получать доступ к памяти только в том случае, если она либо принадлежит исключительно защищенной среде, либо была явно предоставлена ей с использованием FF-A. В системе с S-EL2 обеспечение соблюдения модели доступа к памяти должно осуществляться ядром управления защищенными разделами (SPMC), таким как Hafnium , которое поддерживает таблицы страниц второго этапа для защищенной среды. В системе без S-EL2 TEE может вместо этого обеспечивать соблюдение модели доступа к памяти через свои таблицы страниц первого этапа.
Если вызов SMC к EL2 не является вызовом PSCI или сообщением, определенным FF-A, необработанные вызовы SMC перенаправляются на EL3. Предполагается, что (обязательно доверенное) защищенное программное обеспечение может безопасно обрабатывать необработанные вызовы SMC, поскольку оно понимает меры предосторожности, необходимые для поддержания изоляции pVM.
Монитор виртуальных машин
crosvm — это монитор виртуальных машин (VMM), который запускает виртуальные машины через интерфейс KVM Linux. Уникальность crosvm заключается в его ориентации на безопасность благодаря использованию языка программирования Rust и песочницы вокруг виртуальных устройств для защиты ядра хоста. Более подробную информацию о crosvm можно найти в его официальной документации здесь .
Дескрипторы файлов и ioctl-операторы
KVM предоставляет пользовательскому пространству доступ к символьному устройству /dev/kvm с помощью ioctl-операторов, составляющих API KVM. Эти ioctl-операторы относятся к следующим категориям:
- Системные ioctl-запросы запрашивают и устанавливают глобальные атрибуты, влияющие на всю подсистему KVM, и создают pVM.
- Виртуальные ioctl-запросы запрашивают и устанавливают атрибуты, которые создают виртуальные процессоры (vCPU) и устройства, и влияют на всю виртуальную машину pVM, например, на структуру памяти и количество виртуальных процессоров (vCPU) и устройств.
- С помощью команды ioctl vCPU можно запрашивать и устанавливать атрибуты, управляющие работой отдельного виртуального процессора.
- С помощью ioctl-запросов к устройствам запрашиваются и устанавливаются атрибуты, управляющие работой отдельного виртуального устройства.
Каждый процесс CrosVM запускает ровно один экземпляр виртуальной машины. Этот процесс использует системный ioctl KVM_CREATE_VM для создания файлового дескриптора виртуальной машины, который можно использовать для выполнения ioctl-запросов pVM. ioctl KVM_CREATE_VCPU или KVM_CREATE_DEVICE на файловом дескрипторе виртуальной машины создает виртуальный ЦП/устройство и возвращает файловый дескриптор, указывающий на новый ресурс. ioctl-запросы на файловом дескрипторе виртуального ЦП или устройства можно использовать для управления устройством, созданным с помощью ioctl на файловом дескрипторе виртуальной машины. Для виртуальных ЦП это включает в себя важную задачу выполнения гостевого кода.
Внутри системы crosvm регистрирует файловые дескрипторы виртуальной машины в ядре, используя интерфейс epoll срабатывающий по требованию. Затем ядро уведомляет crosvm всякий раз, когда в любом из файловых дескрипторов появляется новое ожидающее событие.
pKVM добавляет новую возможность, KVM_CAP_ARM_PROTECTED_VM , которая может использоваться для получения информации об окружении pVM и настройки защищенного режима для виртуальной машины. crosvm использует это во время создания pVM, если передан флаг --protected-vm , для запроса и резервирования соответствующего объема памяти для прошивки pVM, а затем для включения защищенного режима.
выделение памяти
Одна из главных задач VMM — выделение памяти для виртуальной машины и управление её структурой. crosvm генерирует фиксированную структуру памяти, приблизительно описанную в таблице ниже.
| FDT в обычном режиме | PHYS_MEMORY_END - 0x200000 |
| Свободное пространство | ... |
| Ramdisk | ALIGN_UP(KERNEL_END, 0x1000000) |
| Ядро | 0x80080000 |
| Загрузчик | 0x80200000 |
| FDT в режиме BIOS | 0x80000000 |
| Физическая база памяти | 0x80000000 |
| прошивка pVM | 0x7FE00000 |
| Память устройства | 0x10000 - 0x40000000 |
Физическая память выделяется с помощью mmap , и эта память передается виртуальной машине для заполнения ее областей памяти, называемых memslots , с помощью ioctl KVM_SET_USER_MEMORY_REGION . Таким образом, вся память гостевой виртуальной машины pVM выделяется экземпляру CrosVM, который ею управляет, и может привести к завершению процесса (прекращению работы виртуальной машины), если на хосте начнет заканчиваться свободная память. При остановке виртуальной машины память автоматически очищается гипервизором и возвращается ядру хоста.
В обычном режиме KVM виртуальная машина сохраняет доступ ко всей памяти гостевой системы. В режиме pKVM память гостевой системы отключается от физического адресного пространства хоста при её передаче гостевой системе. Единственное исключение — память, явно совместно используемая гостевой системой, например, для устройств virtio.
Области MMIO в адресном пространстве гостевой системы остаются неотображенными. Доступ гостевой системы к этим областям перехватывается и приводит к событию ввода-вывода на файловом дескрипторе виртуальной машины. Этот механизм используется для реализации виртуальных устройств. В защищенном режиме гостевая система должна подтвердить использование области своего адресного пространства для MMIO с помощью гипервызова, чтобы снизить риск случайной утечки информации.
Планирование
Каждый виртуальный ЦП представлен потоком POSIX и планируется планировщиком Linux хоста. Поток вызывает ioctl KVM_RUN на файловом дескрипторе vCPU, в результате чего гипервизор переключается в контекст гостевого vCPU. Планировщик хоста учитывает время, проведенное в контексте гостевой системы, как время, используемое соответствующим потоком vCPU. KVM_RUN возвращается, когда возникает событие, которое должно быть обработано VMM, например, ввод-вывод, завершение прерывания или остановка vCPU. VMM обрабатывает событие и снова вызывает KVM_RUN .
В течение KVM_RUN поток остается вытесняемым планировщиком хоста, за исключением выполнения кода гипервизора EL2, который не вытесняется. Сама гостевая виртуальная машина pVM не имеет механизма для управления этим поведением.
Поскольку все потоки vCPU планируются так же, как и любые другие задачи пользовательского пространства, на них распространяются все стандартные механизмы QoS. В частности, каждый поток vCPU может быть привязан к физическим процессорам, помещен в наборы cpusets, ускорен или ограничен с помощью ограничения использования ресурсов, ему может быть изменена политика приоритета/планирования и многое другое.
Виртуальные устройства
CrosVM поддерживает ряд устройств, в том числе следующие:
- virtio-blk для составных образов дисков, только для чтения или для чтения и записи.
- vhost-vsock для связи с хостом
- virtio-pci как транспорт virtio
- Часы реального времени pl030 (RTC)
- UART 16550a для последовательной связи
прошивка pVM
Прошивка pVM (pvmfw) — это первый код, выполняемый pVM, подобно загрузочному ПЗУ физического устройства. Основная цель pvmfw — обеспечить безопасную загрузку и получить уникальный секретный ключ pVM. pvmfw не ограничена использованием с какой-либо конкретной ОС, например, Microdroid , при условии, что ОС поддерживается CrosVM и имеет надлежащую цифровую подпись.
Двоичный файл pvmfw хранится во флэш-памяти в разделе с тем же именем и обновляется по воздуху (OTA) .
Загрузка устройства
В процедуру загрузки устройства с поддержкой pKVM добавляется следующая последовательность шагов:
- Загрузчик Android (ABL) загружает pvmfw из своего раздела в память и проверяет образ.
- ABL получает секреты механизма компоновки идентификаторов устройств (DICE) (составные идентификаторы устройств (CDI) и цепочку сертификатов DICE) от корня доверия.
- ABL вычисляет необходимые CDI для pvmfw и добавляет их к исполняемому файлу pvmfw.
- ABL добавляет в DT узел
linux,pkvm-guest-firmware-memory, указывающий на местоположение и размер исполняемого файла pvmfw, а также секреты, полученные на предыдущем шаге. - ABL передает управление Linux, и Linux инициализирует pKVM.
- pKVM отключает область памяти pvmfw от таблиц страниц второго этапа хоста и защищает её от хоста (и гостевых систем) на протяжении всего времени работы устройства.
После загрузки устройства Microdroid загружается в соответствии с шагами, описанными в разделе «Последовательность загрузки» документации Microdroid .
загрузка pVM
При создании pVM, crosvm (или другой VMM) должен создать достаточно большой memslot, чтобы гипервизор мог заполнить его образом pvmfw. VMM также ограничен в списке регистров, начальное значение которых он может установить (x0-x14 для основного vCPU, отсутствие регистров для дополнительных vCPU). Остальные регистры зарезервированы и являются частью ABI гипервизора-pvmfw.
При запуске pVM гипервизор сначала передает управление основным виртуальным процессором pvmfw. Прошивка ожидает, что crosvm загрузит в память ядро, подписанное AVB (это может быть загрузчик или любой другой образ), а также неподписанный FDT по известным смещениям. pvmfw проверяет подпись AVB и, в случае успеха, генерирует дерево доверенных устройств из полученного FDT, удаляет свои секреты из памяти и переходит к точке входа полезной нагрузки. Если один из этапов проверки не удается, прошивка выполняет гипервызов PSCI SYSTEM_RESET .
В промежутках между загрузками информация об экземпляре pVM хранится в разделе (устройстве virtio-blk) и шифруется с помощью секрета pvmfw, чтобы гарантировать, что после перезагрузки секрет будет предоставлен правильному экземпляру.